智谱发布全新旗舰模型 GLM-5.2:专为长程任务而生
智谱发布全新旗舰模型 GLM-5.2,首次在 100 万 token 超长上下文上实现强大且稳定的长程任务能力,并采用全新 IndexShare 架构与防作弊强化学习技术。
智谱正式推出全新旗舰模型 GLM-5.2,专为长任务而设计。
GLM-5.2 的核心新特性包括:
- 1M 上下文: 能够稳定支撑长程工作流程的 100 万 token 上下文。
- 高级编程能力: 更强大的代码生成与调试能力,支持多种思考强度。
- **架构升级:**提出了 IndexShare 架构,四个稀疏注意力层之间复用同一个索引器(indexer),从而在 1M 上下文长度下使每 token 计算量降低了 2.9 倍。
- 彻底开源: 采用 MIT 开源协议,无地区限制,技术无国界。
先看评测数据
为了支持长线任务,模型不仅要能接收更多的 token,还必须在长而复杂的 coding agent 运行过程中保持高质量的输出。
为此,智谱针对 coding agent 场景大幅扩展了 1M 上下文的训练,涵盖了大规模代码实现、自动化研究、性能优化以及复杂调试。
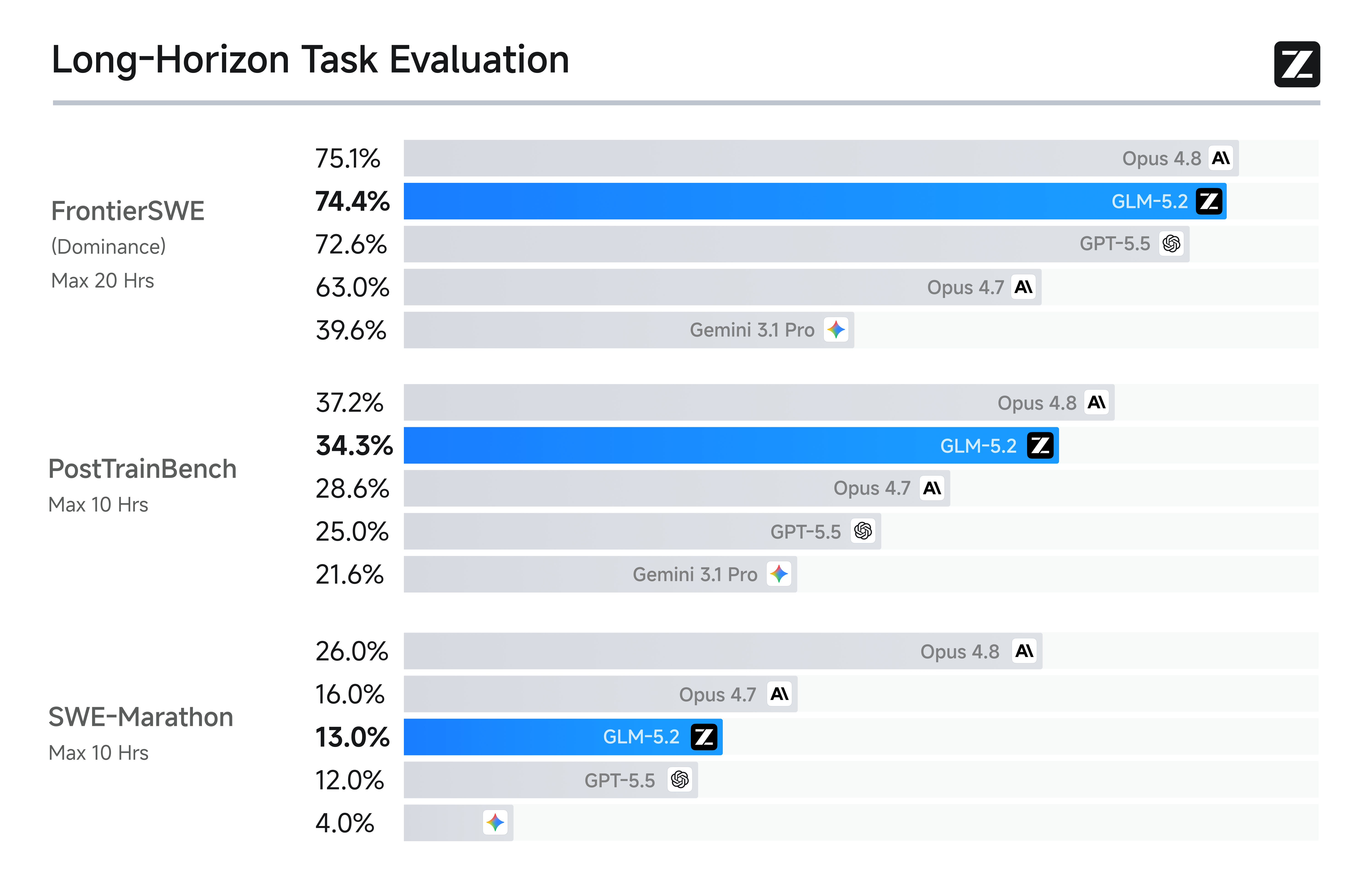
- 在 FrontierSWE 的基准测试中,GLM-5.2 仅落后 Opus 4.8 约 1%,同时领先 GPT-5.5 1%、领先 Opus 4.7 11%。
- 在 PostTrainBench 的测试中,GLM-5.2 的表现超越了 Opus 4.7 和 GPT-5.5,排名仅次于 Opus 4.8。
- 在 SWE-Marathon 的超长程软件工程基准测试中,GLM-5.2 仍有提升空间,落后 Opus 4.8 13%,但依然稳居第二,仅次于 Opus 系列。
在所有这三项基准测试中,GLM-5.2 都是排名最高的开源模型,表明其 1M 上下文已成功转化为实际的交付能力。
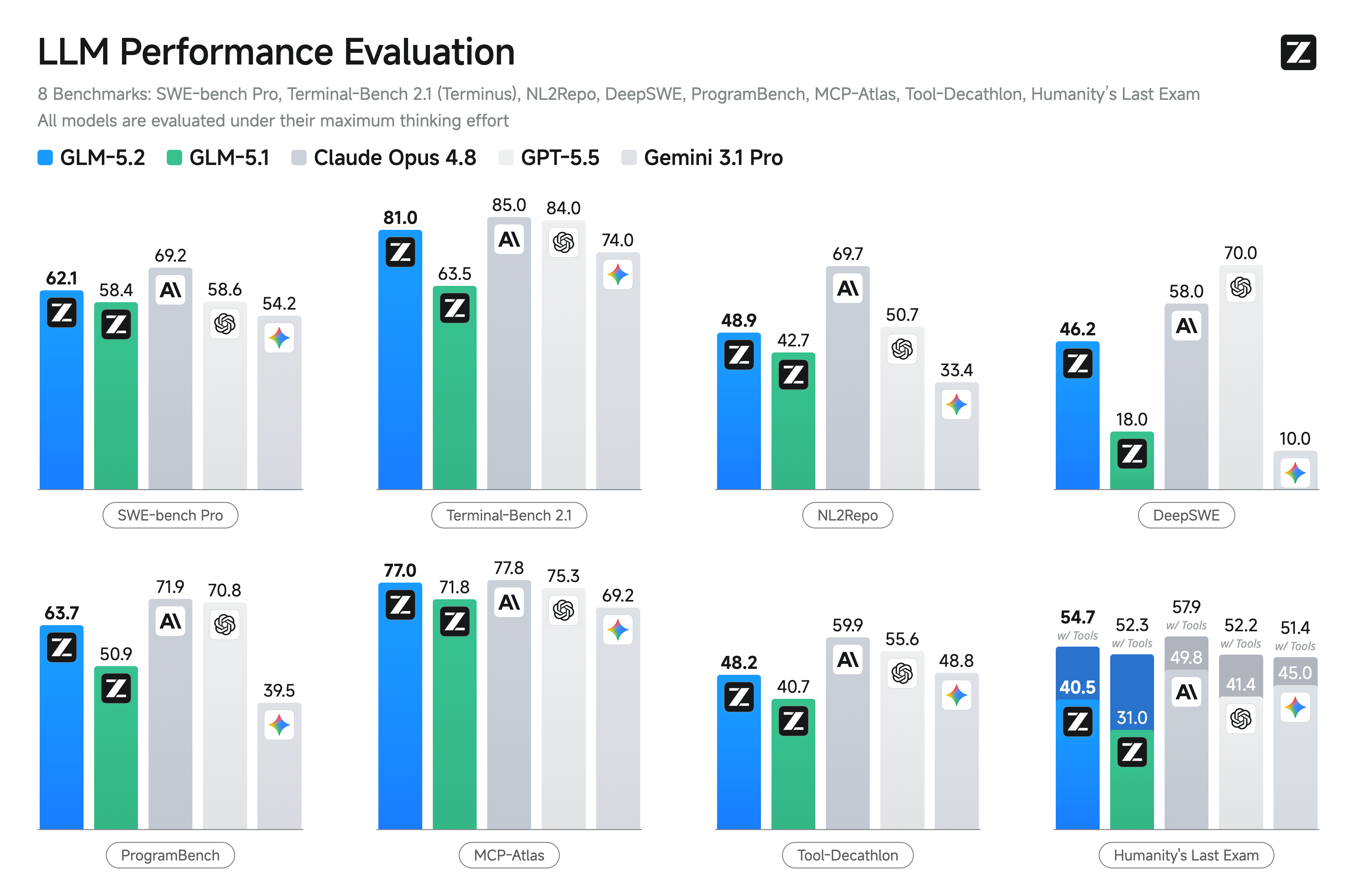
在标准编码基准测试中,GLM-5.2 同样是性能最强的开源模型,相比 GLM-5.1 实现了大幅提升:在 Terminal-Bench 2.1 上得分 81.0(前代为 63.5),在 SWE-bench Pro 上得分 62.1(前代为 58.4)。
同时,它也大幅缩小了与最顶尖闭源模型的差距。在 Terminal-Bench 2.1 上,它以 81.0 的成绩紧咬 Claude Opus 4.8(85.0),并继续领先 Gemini 3.1 Pro。
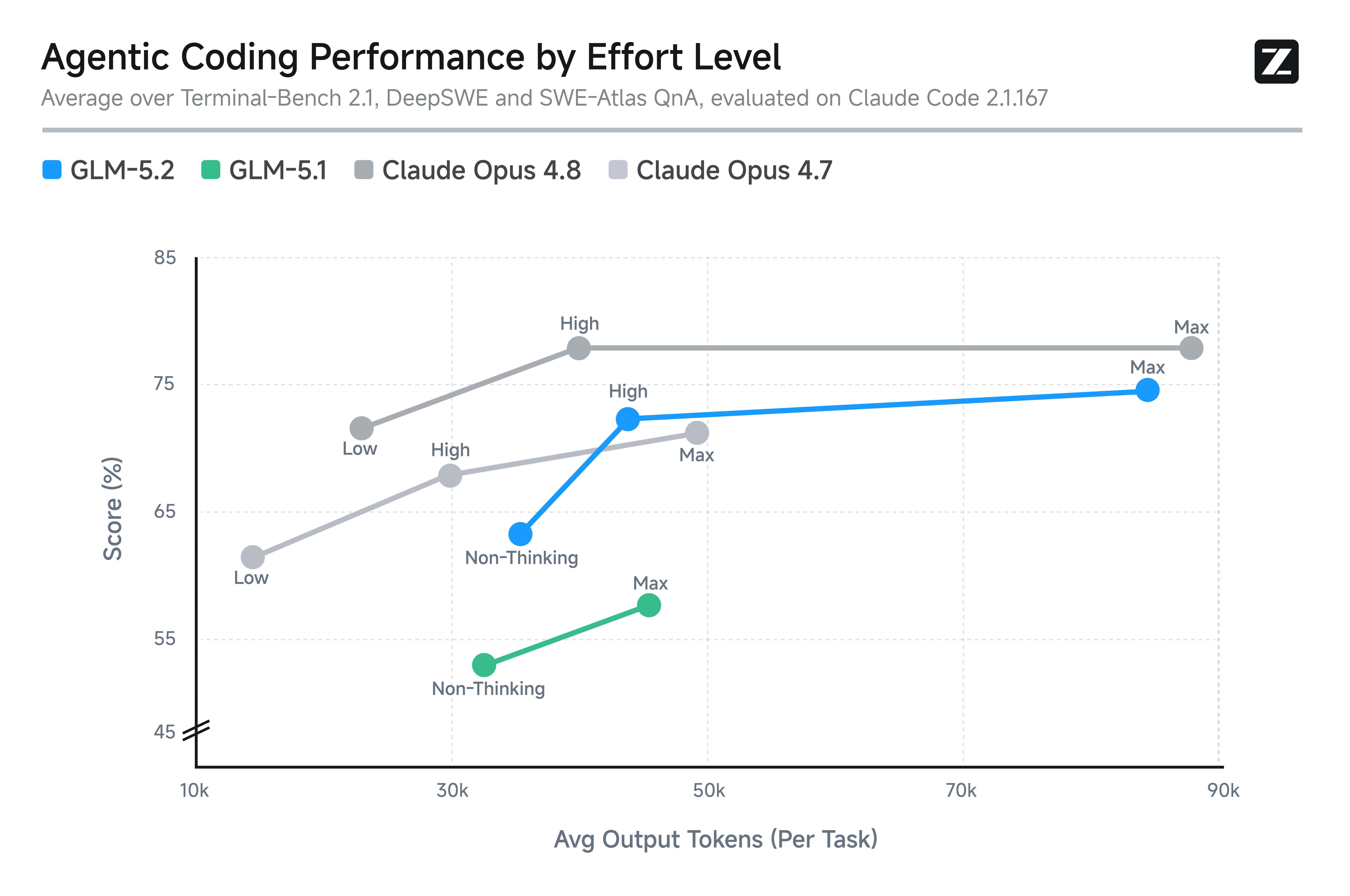
新一代 GLM-5.2 还引入了思考强度控制。
在相近的 token 预算下,GLM-5.2 提供的 agent 编码性能显著强于 GLM-5.1,其能力在同等 token 消耗下大致介于 Claude Opus 4.7 和 Claude Opus 4.8 之间。
开始使用 GLM-5.2
**针对 GLM Coding Plan 订阅用户:**智谱已面向所有 Coding Plan 用户上线了 GLM-5.2。现在可以直接通过将模型名称更新为 "GLM-5.2"(或者在 Claude Code 中使用 "GLM-5.2[1m]" 以启用 1M 上下文长度)来开启体验。
GLM-5.2 的额度消耗在高峰时段为 3 倍,非高峰时段为 2 倍。作为限时福利,即日起至 9 月底,非高峰时段的使用将按 1 倍计费。(高峰时段为北京时间每日 14:00–18:00)。
同时,更喜欢图形用户界面的用户可以使用 ZCode。它支持处理长程任务的 /goal 功能、SSH 远程开发以及手机控制。
在 ZCode 中通过 Coding Plan 使用 GLM-5.2,可在 6 月 30 日前享受 1.5 倍的有效额度。
同时,GLM-5.2 已同步在 Z.ai 上线。