Anthropic 官方指南:5 种多 Agent 模式,帮你解决真实业务难题【译】
对 Anthropic 官方发布的多 Agent 协作模式指南进行了深度总结,包括生成器-验证器、协调者-子代理、团队模式、消息总线和共享状态五种架构的工作原理、适用场景与实现难点。
原文链接: https://claude.com/blog/multi-agent-coordination-patterns
Anthropic 出了一篇多 Agent 协作模式指南,总结了 5 种架构和适用场景。
文章中专门提到,不少团队在选型时的依据是“听起来够不够高级”,而不是“是否适合当前问题”。而 Anthropic 建议是不要让协调复杂度超过任务本身的复杂度。
这篇干货很足,分享总结如下:
1. 生成器 - 验证器
这是最简单的多代理模式,也是部署最广泛的模式之一。
工作原理
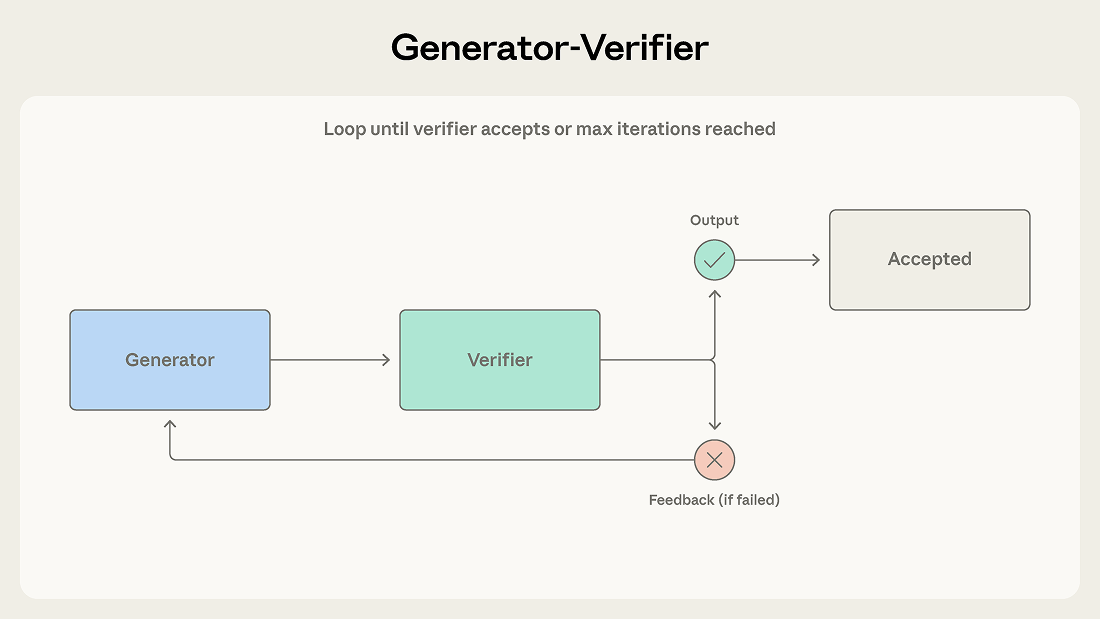
- 生成器接收任务,生成初始输出,传递给验证器进行评估。
- 验证器检查是否符合要求,并决定接受或拒绝,并提供反馈。
- 如果拒绝,则将反馈返回给生成器,生成器继续修改。
- 此循环持续进行,直到验证器接受输出或达到最大迭代次数为止。
适用场景
它适用于代码生成(一个代理编写代码,另一个代理编写并运行测试)、事实核查、基于评分标准的评分、合规性验证,以及任何错误输出成本超过额外生成周期的领域。
难点
验证器的效果,完全取决于它的评估标准。如果你只告诉验证器“检查输出好不好”,却没有给出更具体的标准,它往往会对生成器的输出进行机械式的认可。
另外,迭代循环可能会停滞。如果生成器无法处理验证者的反馈,系统就无法靠近预期结果。设置最大迭代次数限制并采用回退策略(例如将问题提交给人工处理)可以防止这种情况演变为无限循环。
2. 协调者 - 子代理
这个模式的核心是层级结构。一个代理扮演“团队负责人”的角色,负责规划工作、分配任务、汇总结果。子代理负责具体职责并向上汇报。
工作原理
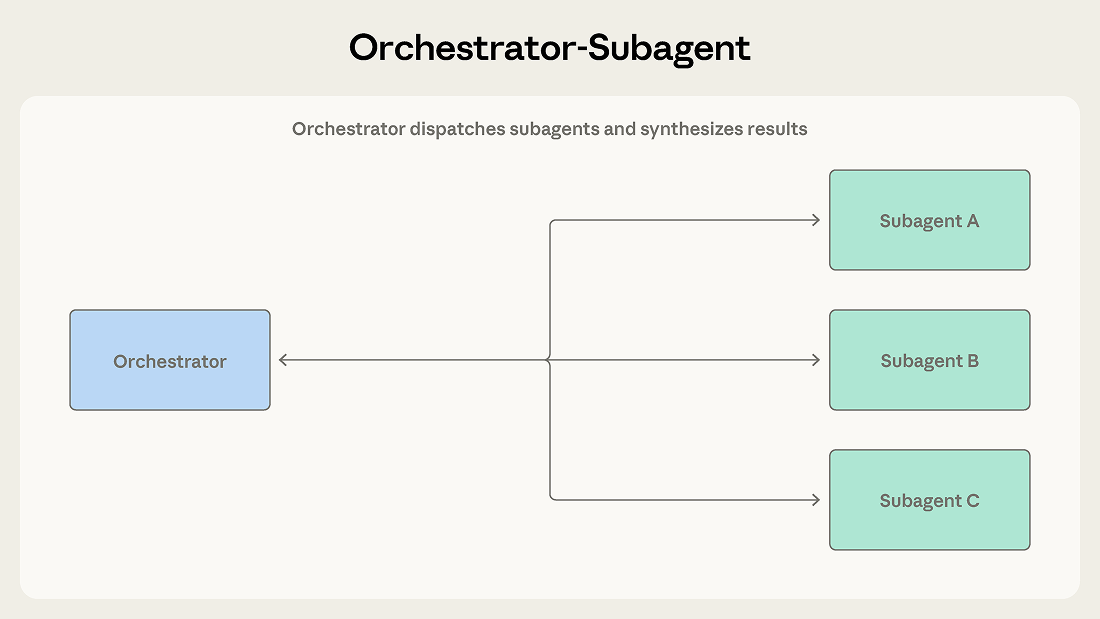
- 主代理接收任务后,决定整体处理方式。
- 它可能先完成一部分子任务,也可能把其他派发给子代理
- 子代理完成各自工作后返回结果,再由协调者统一整合成最终输出。
Claude Code 内部采用的就是这种模式。主代理自行编写代码、编辑文件和运行命令,并在需要搜索大型代码库或调查独立问题时,在后台调度子代理,从而确保工作持续进行,同时结果不断返回。
适用场景
当任务拆解足够清晰、子任务之间依赖很少时,这种模式尤其合适。协调者负责把握整体目标,子代理专注于各自的职责。
难点
当某个子代理发现了一条对另一个子代理有价值的信息时,信息会先回到协调者,再由协调者判断是否需要转发。
类似的往返一多,关键细节就很容易在中间被遗漏,或者被过度摘要。
3. 团队模式
当任务可以被拆成多个并行子任务,而且每个子任务都能独立持续一段时间时,“协调者 - 子代理”就会显得过于拘束。
工作原理
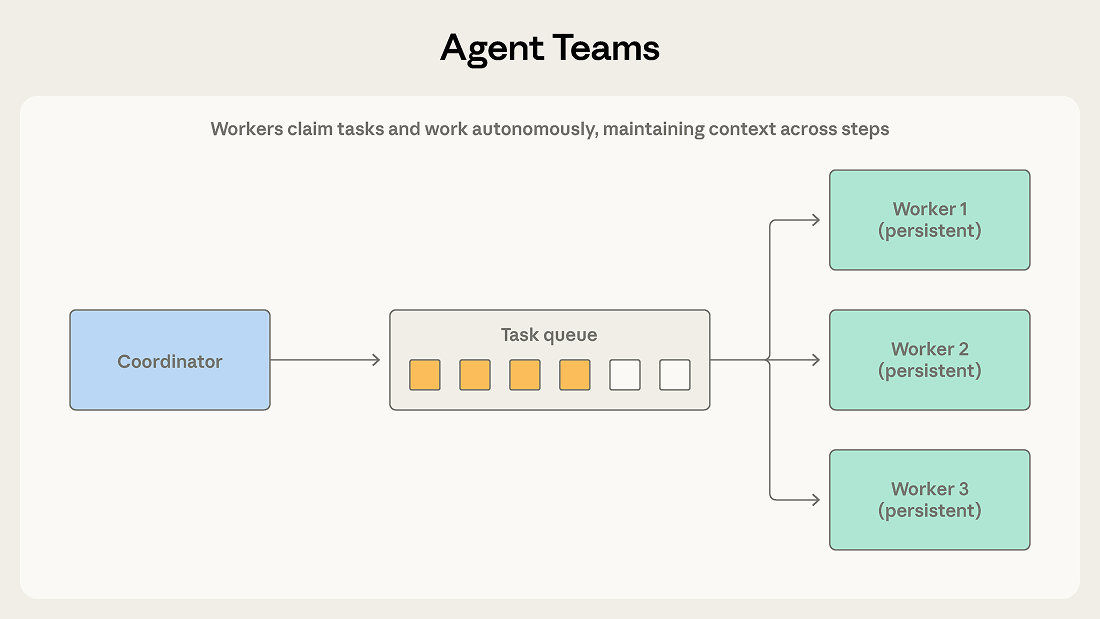
协调器会生成多个工作代理作为独立进程。团队成员从共享队列中领取任务,自主地分多个步骤完成任务,并发出完成信号。
适用场景
当子任务彼此独立,且需要持续的多步骤协作时,可以使用这种模式。每个团队成员都能逐步积累各自领域的相关知识,而不是每次任务都从零开始。
难点
- 代理团队中的成员自主运行,无法共享中间进程,可能会产生冲突的结果。
- 完成状态难判断
共享资源会把这两个问题进一步放大。如果多个成员同时操作同一个代码库、数据库或文件系统,他们可能会改到同一个文件,或者做出彼此不兼容的修改。
因此,这种模式通常需要非常细致的任务切分和明确的冲突解决机制。
4. 消息总线
当代理数量继续增加、它们之间的交互路径也越来越复杂时,靠点对点协调会很难维护。消息总线模式会引入一个共享通信层,让各个代理通过发布和订阅事件来协作。
工作原理
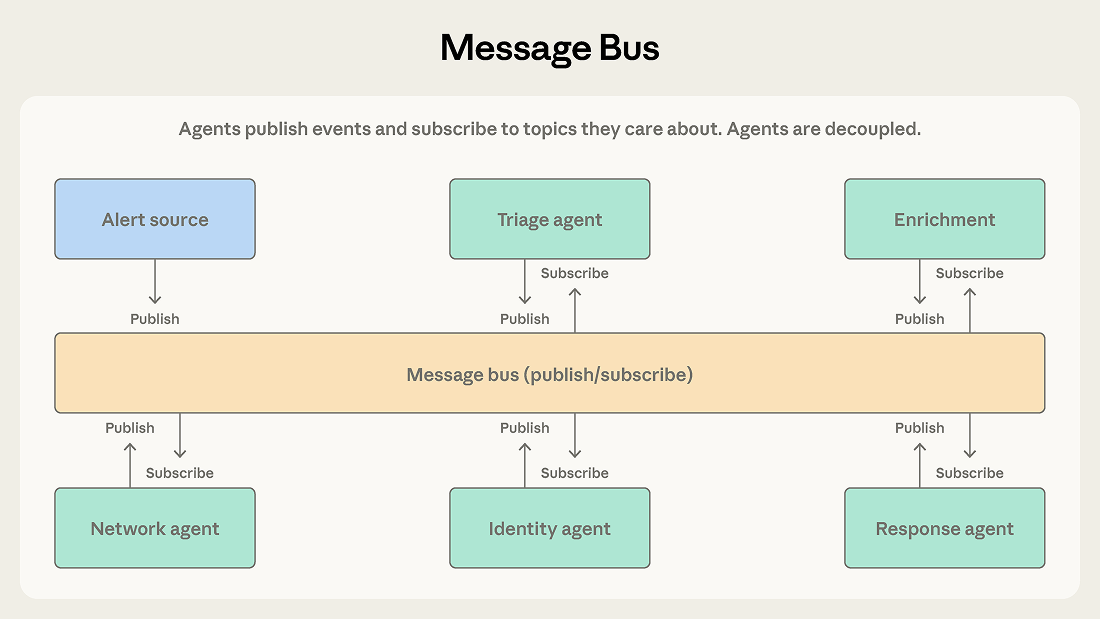
代理之间只依赖两个基础动作:发布和订阅。
每个代理订阅只关心自己的主题,拥有新功能的代理无需重新配置现有关联逻辑即可开始接收相关任务。
适用场景
例如自动化安全检测系统。
警报来自多个来源,分类代理会根据严重性和类型对每个警报进行分类,将高严重性网络警报路由至网络调查代理,将凭证相关警报路由至身份分析代理。每个调查代理都可以发布信息增强请求,由上下文收集代理执行。调查结果最终会传递给响应协调代理,由其确定相应的应对措施。
这类流水线非常适合消息总线,因为事件会自然地从一个处理阶段流向下一个阶段;随着威胁类型不断变化,团队还可以持续加入新的代理类型;同时,不同代理也能独立开发和部署。
难点
事件驱动通信虽然灵活,但也让问题追踪变得更困难。
当一个告警触发了跨越五个代理的一连串事件时,想要搞清楚到底发生了什么,往往必须依赖极其完善的日志和关联追踪,调试成本会高很多。
5. 共享状态
前面几种模式里,本质上都在中心化地控制信息流。共享状态模式拿掉了这个中间层,让所有代理直接通过同一个持久化存储进行协作。
工作原理
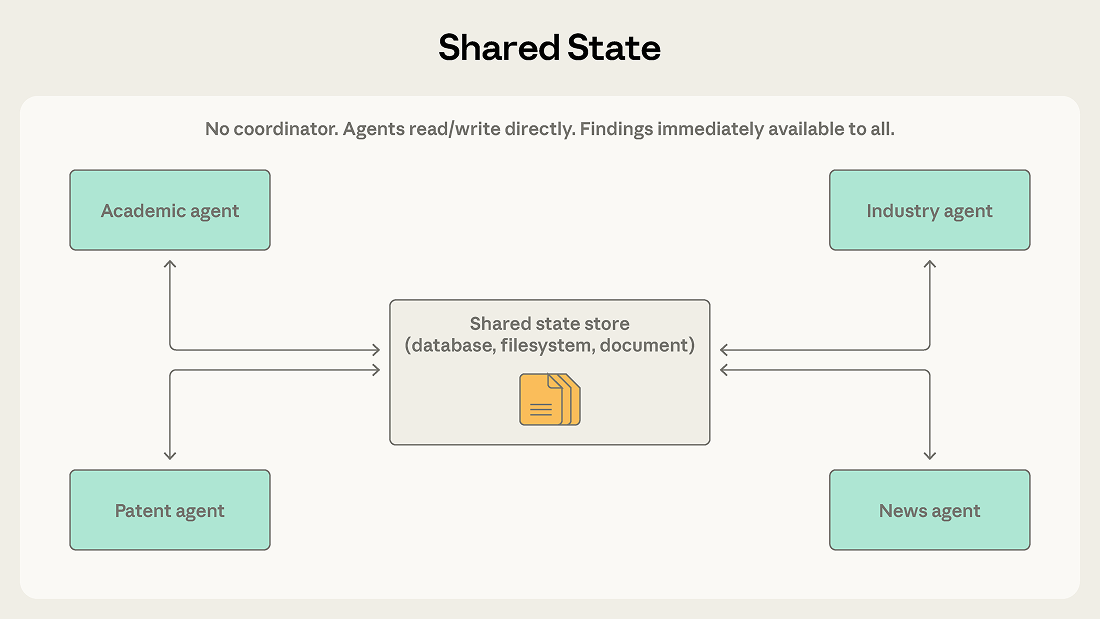
代理程序自主运行,从共享数据库、文件系统或文档读取数据并写入数据。没有中央协调器。
每个代理都会去检查共享存储里有没有与自己相关的信息,基于已有内容采取行动,并将结果写回存储库。
适用场景
综合调研查询类的系统很能体现这种模式的优势。
多个代理分别从复杂问题的不同角度展开调查:一个查学术文献,一个分析行业报告,一个研究专利申请,另一个持续跟踪新闻报道。
在共享状态模式下,这些发现会直接写入共享存储。行业分析代理可以立刻看到学术代理的新发现,而不需要等待某个协调者帮它转发。代理之间能够真正建立在彼此成果之上继续推进,共享存储本身也会逐渐演化成一个动态增长的知识库。
难点
缺乏显式协调指令时,代理可能会重复劳动,或者朝着互相矛盾的方向前进。
如何使用
下面这张表总结了各种模式的适用场景:
| 场景 | 模式 |
|---|---|
| 输出质量要求极高,且评估标准明确 | 生成器-验证器 |
| 任务拆解清晰,子任务边界明确 | 协调者-子代理 |
| 工作负载可并行,且子任务独立、持续时间长 | 团队模式 |
| 流程由事件驱动,代理生态会持续扩张 | 消息总线 |
| 协作式研究,代理需要共享发现 | 共享状态 |
| 必须避免单点故障 | 共享状态 |
对大多数场景来说,建议先从协调者-子代理开始。因为它最简单,也覆盖了开发中最常遇到的问题。如果观察到哪些方面存在不足,再根据具体需求逐步过渡到其他模式。