开发者在 GitHub 上实锤 Claude 思考深度暴跌 67%
对 GitHub 上关于 Claude Code 性能下降的定量分析 Issue 进行了深度解读,揭示了“先思考”向“先编辑”的工作模式转变、思考深度暴跌与各种逃避行为的关联。
最近,有开发者在 Claude Code 官方仓库提了个 issue,提出「2 月份的更新导致 Claude Code 无法执行复杂的工程任务」。
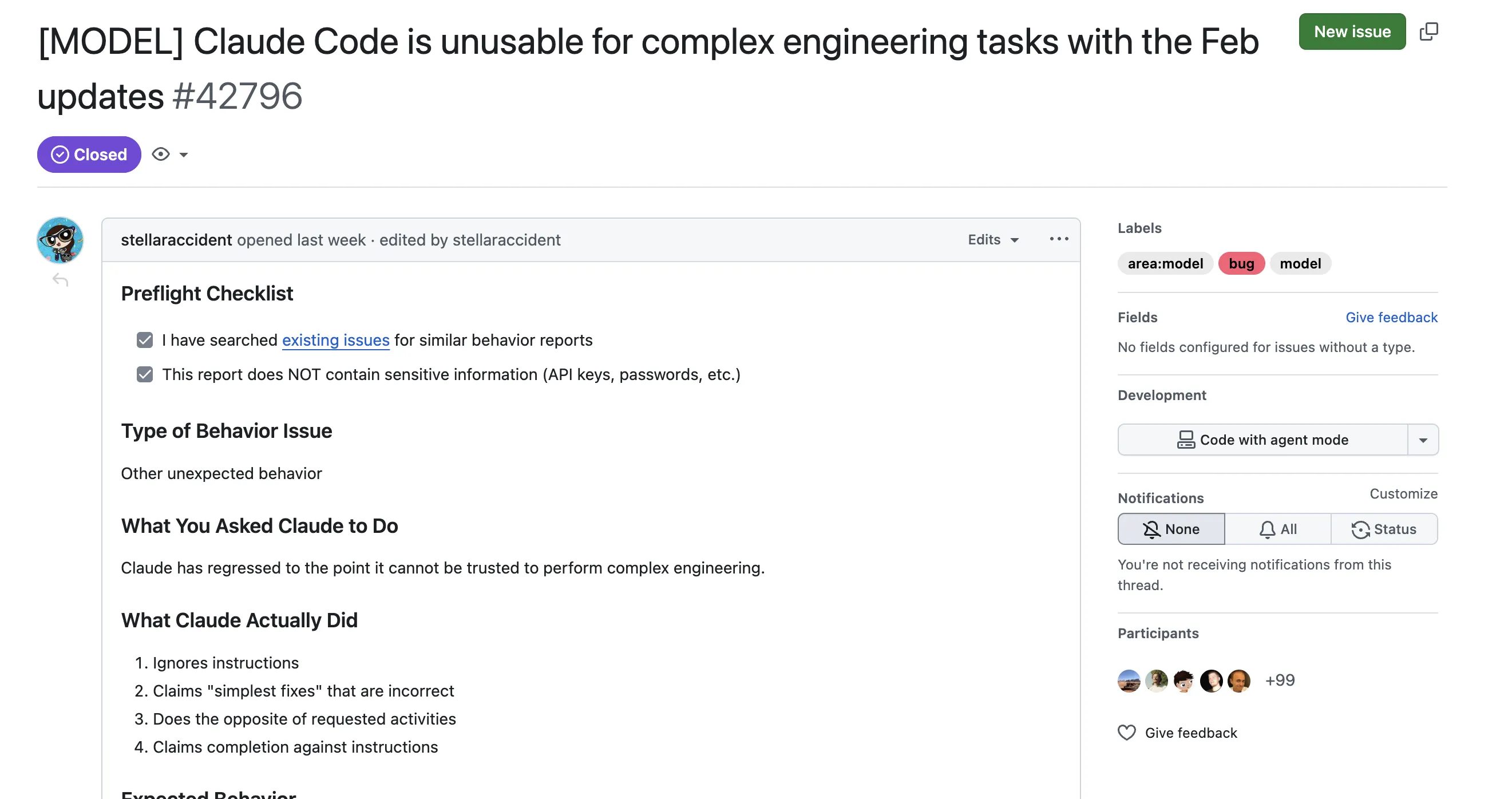
他提到的具体现象为:
- 忽略指令
- 声称的“最简单的解决方法”是错误的
- 执行与要求相反的操作
- 完成标准与指令不符
而且这并不是单纯根据现象推测的,开发者在 issue 中直接甩出了研究报告。
他对 6852 个 Claude Code 会话文件中的 17871 个思考模块和 234760 次工具调用进行的定量分析表明,2 月的更新与复杂长会话工作流中测得的质量下降存在明确关联。现在 Claude 模型的工作模式会明显从“先思考”转向“先编辑”,从而导致严重的质量问题。
完整过程
Claude Code 在最近的更新中,为了“反蒸馏“发布了一项名为 redact-thinking 的特性,该特性会隐藏模型的思考链。Claude 给出的说法是,大多数用户都不会查看思考过程,而且隐藏并不会影响思考过程,也不会影响思考预算和底层扩展推理的方式,它只是 UI 界面上的改动。
事实果真如此吗?下面是 Github issue 中列出的部分研究数据:
1. 验证 redact-thinking 的特性的推送方式
对 JSONL 文件中 thinking token 进行分析,可推算出 redact-thinking 的推送方式:
| 日期 | 可见思考过程 | 不可见思考过程 |
|---|---|---|
| 1月30日至3月4日 | 100% | 0% |
| 3月5日 | 98.5% | 1.5% |
| 3月7日 | 75.3% | 24.7% |
| 3月8日 | 41.6% | 58.4% |
| 3月10日至11日 | <1% | >99% |
| 3月12日以后 | 0% | 100% |
3 月 8 日,有独立报道指出 Claude 的质量出现下滑,而该日期正是 Claude redact-thinking feature 占比突破 50% 的日期。它的推送模式是一周内 1.5% → 25% → 58% → 100%,完全符合分阶段部署的情况。
2. 在 redact-thinking 之前,思考深度就已经下降了
| 日期 | 预计思考量(字符) | vs 基准线 |
|---|---|---|
| 1月30日至2月8日(基线) | ~2,200 | — |
| 二月下旬 | ~720 | -67% |
| 3月1日至5日 | ~560 | -75% |
| 3月12日及之后(完全推出 redact-thinking 功能后) | ~600 | -73% |
到 2 月底,思维深度已经下降了约 67%。3 月初推出的这项屏蔽措施使用户无法察觉到这一点。
3. 对质量的影响
这些指标是根据 18000 多条 prompt 独立计算得出的。
| 指标 | 3月8日之前 | 3月8日之后 | 改变 |
|---|---|---|---|
| 中断钩子触发次数 (惰性拦截) | 0 | 173 | 0 → 10/天 |
| prompt 中的挫败感指标 | 5.8% | 9.8% | +68% |
| 需要纠正规避所有权的行为 | 6 | 13 | +117% |
| 每次会话提示 | 35.9 | 27.9 | -22% |
| 包含推理循环的会话(5+) | 0 | 7 | 0 → 7 |
我们开发了一个中断钩子(stop-phrase-guard.sh),用于通过编程方式捕获规避所有权、过早终止以及请求权限的行为。自 3 月 8 日以来,该钩子在 17 天内触发了 173 次。在此之前,它从未触发过。
4. 工作模式从“思考优先“变成了“编辑优先“
对 234760 次工具调用的分析表明,模型在修改代码之前就停止了读取代码。
“读取“与“编辑“数据对比
| 日期 | 读取次数:编辑次数 | 研究次数:修改次数 | 读取比例 % | 编辑比例 % |
|---|---|---|---|---|
| 良好(1月30日-2月12日) | 6.6 | 8.7 | 46.5% | 7.1% |
| 过渡期(2月13日-3月7日) | 2.8 | 4.1 | 37.7% | 13.2% |
| 降级(3月8日-3月23日) | 2.0 | 2.8 | 31.0% | 15.4% |
模型从每次编辑需要 6.6 次文件读取,减少到每次编辑只需要 2.0 次读取。减少了 70%。
过去模型运行良好的时期,Claude 的工作流程是:读取目标文件,读取相关文件,在整个代码库中搜索用法,阅读头文件和测试用例,然后进行精确编辑。
而在性能下降的时期,Claude 仅读取当前文件并进行编辑,通常不检查上下文。
周趋势
Week Read:Edit Research:Mutation
──────────────────────────────────────────
Jan 26 21.8 30.0
Feb 02 6.3 8.1
Feb 09 5.2 7.1
Feb 16 2.8 4.1
Feb 23 3.2 4.5
Mar 02 2.5 3.7
Mar 09 2.2 3.3
Mar 16 1.7 2.1 ← lowest
Mar 23 2.0 3.0
Mar 30 1.6 2.6研究投入的减少始于 2 月中旬,这与估算的思考深度下降 67% 的时间段相完全吻合。
“写入“与“修改“数据对比
| 日期 | 所有修改中的“直接写入“占比 |
|---|---|
| 良好(1月30日-2月12日) | 4.9% |
| 降级(3月8日-3月23日) | 10.0% |
| 最后(3月24日-4月1日) | 11.1% |
全文件写入的使用量翻了一番。模型越来越倾向于重写整个文件,而非进行精准编辑。虽然重写速度更快,但会牺牲精度和上下文感知能力。
其它数据
开发者还列出了很多开发过程中遇到的问题和统计数据,下面我列出几个比较有意思的:
“Simplest Fix“心态
模型输出中的“simplest(最简单)”一词表明,它正在优化,以求耗费最少精力,而非评估正确的解决方案。在深度思考中,模型会评估多种方案并选择最合适的那个;而在浅层思考中,它则倾向于选择那些最不需要通过推理来论证的方案。
| 时期 | 每 1000 次调用中出现“最简单”的次数 |
|---|---|
| 好的 | 2.7 |
| 降级 | 4.7 |
| 最后 | 6.3 |
在某次长达 2 小时的观察期间,该模型 6 次采用了“最简单”的方案,而其生成的代码却被其后期的自我修正机制描述为“懒惰并错误”、“仓促”和“草率”。每次,Claude 都选择了一种避开更棘手问题的方法,转而采用一种表面上的权宜之计。
提前终止任务
模型具备深度思考能力,能够评估任务是否完成,并自主决定是否继续执行。而具备浅层思考能力的模型则会默认停止并向用户请求许可,这是成本最低的操作。
为此,我们构建了一个程序化的停止钩子,用于捕获这些短语并强制继续执行。捕获到的违规类别包括:
| 类别 | 计数(3月8日至25日) | 示例 |
|---|---|---|
| 逃避所有权 | 73 | “并非由我的更改引起”,“已存在的问题” |
| 寻求许可 | 40 | “我应该继续吗?”,“你想让我继续吗?” |
| 提前终止 | 18 | “良好停止点”,“检查点” |
| 预判局限性 | 14 | “已知局限性”、“未来工作” |
| 会话长度限制 | 4 | “在新会话中继续”,“时间过长” |
| 总计 | 173 | |
| 3月8日之前 | 0 |
这个钩子的存在,本身就是模型退化的证据。在 Claude 运行良好的时期,它本是不需要的,因为模型从未表现出这些行为。钩子中的每一行代码都是针对模型试图过早停止运行的特定事件而添加的。
模型主动认错
在性能退化期间,Claude 模型在经过修正后,经常主动承认生成的内容质量较差。这些“认错“是在用户指出问题后,模型意识到自己之前为了图省事而做出的妥协:
- “你说得对,那确实是懒惰且错误的做法。我当时只是想回避代码生成的问题,而不是去解决它。“
- “你说得对,我做得太仓促了,结果显而易见。”
- “你说得对,我的确太粗心了。“
| 时期 | 每 1000 次调用的“认错“数 |
|---|---|
| 好的 | 0.1 |
| 降级 | 0.3 |
| 最后 | 0.5 |
在这些案例中,模型本身意识到了输出结果未达标,但这是在经过外部修正之后才发现的。如果具备足够的推理深度,这些错误本应在推理过程中被内部检测出来,从而避免产生错误的输出结果。模型清楚什么是优质的结果,它只是没有足够的资源来进行检查。
看完这些问题和场景,是不是感觉自己也中招过很多次。因为这不是错觉,只是终于有人较真地把这些数据都量化分析出来了。完整数据可以去 Github issue 中查看。
后续
数据在 Github 上炸锅后,Claude Code 团队出来发布了回应:
Opus 4.6 支持自适应思维,在这种模式下,模型会决定思考的时间长短,这通常比固定的思维预算效果更好。
有些人希望模型思考更长时间,即使这意味着需要更多的时间和 token。
接下来,我们将测试将 Teams 和企业版用户的默认设置设为 high-effort 模式,以便他们能够充分思考,即使这意味着需要消耗更多令牌并增加延迟。此默认设置可以通过
/effort和settings.json文件以完全相同的方式进行配置。
Claude 团队的回应承认了“自适应思维”的权衡,并承诺为高要求用户提供“高投入模式”。
问题的根源,并不在于用户有没有打开那个更高预算的开关,而是 Claude 本该具备的严谨推理,已在算力压力的迭代中被系统性牺牲。
目前,该 issue 的状态为“已关闭”,这本身就已经说明了 Claude 的态度。
Github issue:https://github.com/anthropics/claude-code/issues/42796
Claude 团队回应:https://news.ycombinator.com/item?id=47664442