Github 12 万个 star 的 karpathy-skill 到底是什么神仙技能
Andrej Karpathy 的 Claude.md 抱怨贴如何演变成 GitHub 12 万 Star 的规则,以及开发者对其进行的进一步补充与优化实践。
还有人没用过 andrej-karpathy-skills 吗?
2026 年 1 月下旬,Andrej Karpathy 发帖抱怨 Claude 的 Coding 流程。
他列举了三个自己经常遇到的问题:错误假设、过度复杂化,以及对不该涉及的代码造成破坏。
然后 github 上一个名为 forrestchang 的开发者看到了这篇帖子和下面的讨论。于是将这些抱怨整理成 4 条规则,并写入一个名为 CLAUDE.md 的文件发布到 GitHub 上。
结果该仓库一夜爆火,首日便斩获 5828 个 star,截止目前竟已突破 12 万个 🌟。
为何有效
Claude Code 的 CLAUDE.md 文件是整个 AI 代码库中最被低估的文件。
大多数开发者的使用方式如下:
- 一股脑把自己所有偏好和习惯写入该文件,导致 token 急速膨胀。
- 完全不使用
CLAUDE.md,而是每次写下重复的提示词,甚至不同会话之间表述不一致。 - 只复制粘贴一次模板后就不管了。它通常能正常运行一段时间,然后随着代码库变化慢慢失效。
Anthropic 的官方文档明确指出:CLAUDE.md 仅供参考。
Claude 大约 80% 的情况下会遵循它,但超过 200 行后,遵循率会急剧下降,因为重要的规则会被淹没在无关信息中。
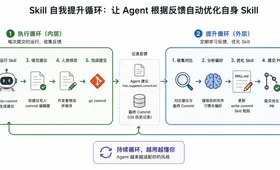
andrej-karpathy-skills 用一个文件、65 行代码、4 条规则就解决了这个问题。
最初的 4 条规则
规则一
Think Before Coding,编码前先思考。
不要妄下定论。不要掩饰困惑。要权衡利弊。
- 明确说明你的假设,如有疑问,需提出。
- 如果存在多种方案,需全部提出,不要暗自做出选择。
- 如果存在更简单的方法,需提出,必要时要敢于提出异议。
- 如果有什么不明白的地方,停下来。说出困惑,提出疑问。
规则二
Simplicity First,简单至上。
用最少的代码解决问题,不要进行任何推测。
- 没有超出要求范围的功能。
- 没有一次性代码。
- 对于不可能出现的情况,不进行错误处理。
- 如果你写了 200 行代码,结果发现其实 50 行就够了,那就重写。
问问自己:“高级工程师会认为这过于复杂吗?” 如果是,则简化它。
规则三
Simplicity First,简单至上。
Simplicity First,简单至上。
编辑现有代码时:
- 不要“改进”相邻的代码、注释或格式。
- 不要重构没有问题的代码。
- 保持当前代码风格。
- 如果你发现了无效代码,指出它,不要删除它。
当你的更改导致了孤留文件时:
- 删除因修改而产生的不再使用的导入项、变量和函数
- 除非被要求,否则不要删除已有的无效代码。
测试要求:每一行修改都应该能直接追溯到用户的需求。
规则四
Goal-Driven Execution,目标驱动执行。
定义明确的成功标准,循环执行直至验证通过。
将任务转化为可验证的目标:
- 添加验证:编写针对无效输入的测试,并确保通过。
- 修复漏洞:编写一个能复现该问题的测试,并确保通过。
- 重构:确保重构前后测试都能通过。
对于多步骤任务,需简要说明计划:
1. [Step] → verify: [check]
2. [Step] → verify: [check]
3. [Step] → verify: [check]明确的成功标准能让你独立自主迭代,模糊的标准(比如:让它运行起来)需要不断地解释说明。
优化空间
如今的 Claude Code 生态系统又出现了更多新的问题,比如多 Agent 冲突、级联 Hook 调用、技能加载冲突、多步骤工作流在跨会话时意外中断等等。
一位叫 Mnimiy 的开发者发现 karpathy 这四种方法可以解决他在 Claude Code 会话中观察到的约 40% 的异常,而剩余的约 60% 存在于以下几个方面。

于是,他针对这些场景又提出了 8 条规则,下面我会列举比较实用的几条:
新增规则
严格遵循 token 预算
使用场景:
没有预算的 Agent 就像一张空白支票,每次任务都有可能跑出 5 万个 token 的上下文。
规则内容:
- 单次任务预算:4000 个 token。
- 单个会话预算:30000 个 token。
- 如果某项任务即将达到预算上限,立刻总结工作并重新开始,切勿强行继续。
- 及时发现超额,不要暗自超出预算。
这对于 token 不够花的用户非常有效。
不要试图制造表面平和的假象
使用场景:
当代码库中两个部分的内容或意见不一致时,Agent 通常会试图让双方都满意,结果导致代码混乱不堪。
规则内容:
- 如果代码库中存在两种相互矛盾的方案,不要混合使用。
- 选择其中一种(更新的 or 测试用例更多的),解释原因,并标记另一种以便清理。
折中方案是最差的方案。
编码前先阅读
使用场景:
Karpathy 的「修改边界」告诉 Agent 不要修改相邻的代码,但并没有告诉他要先理解相邻的代码。因此 Agent 编写的新代码可能会与其它代码发生冲突。
规则内容:
- 在编写代码之前,先阅读该文件的导出内容及调用者。
- 如果你不明白现有代码为何采用当前的结构,在编码前先询问。
在我看来“这似乎是相互独立的”是 Agent 说过的最危险的话。
测试不是最终目标
使用场景:
Karpathy 的目标驱动执行理念将测试作为了成功标准。但在实际使用过程中,Agent 通常会将“测试通过”视为唯一目标,编写的代码的确通过了测试,但却破坏了一些其它功能。
规则内容:
- 测试必须体现该功能的重要性,而不仅仅是逻辑。
- 如果函数接受的是硬编码的 ID,那么像
expect(getUserName()).toBe(‘John’)这样的测试就毫无价值。 - 如果无法编写出在业务逻辑变更时会失败的测试,那么该测试是有问题的。
其它规则
其它完整 8 条规则可以去这个链接查看: https://x.com/Mnilax/status/2053116311132155938
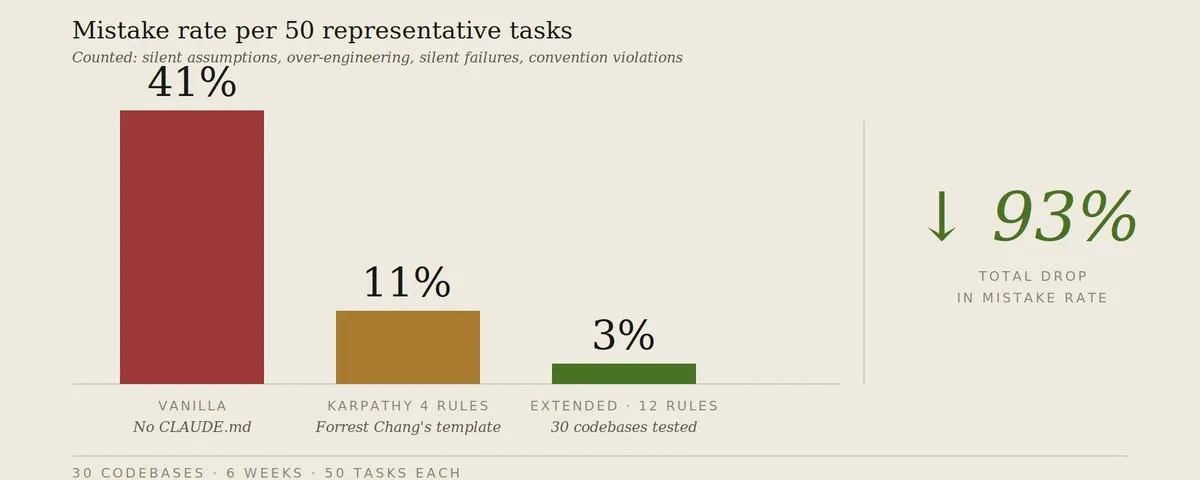
作者经过 6 周时间用 30 个代码库进行了测试,发现这些规则在发挥其优势的任务中,原本约 40% 的错误率能下降到 3% 以下。
最后总结
CLAUDE.md 不是“愿望清单“,而是一份行为契约,用于解决你所观察到的特定失败模式。
所以在编写你自己的规则时,至少遵循:每条规则都应该回答“这条规则能防止什么错误?“
Karpathy 在 2026 年 1 月发的帖子原本是一篇抱怨帖,结果 forrestchang 将其整理成了 4 条规则,12 万名开发者为其点赞。
时至今日,其中大部分开发者,包括我仍然在遵循这 4 条规则。
但模型已经改进,生态系统也发生了变化,或许你的约束也该跟着变一下。